In this blog will try to show that analysis based on a single heap dump can also be an extremely powerful means of finding memory leaks. I will give some tips how to obtain data suitable for the analysis. I will then describe how to use the automated analysis features of the Memory Analyzer tool, which was contributed several months ago to Eclipse. Automating the analysis greatly reduces the complexity of finding memory problems, and enables even non-experts to handle memory-related issues. All you need to do is provide a good heap dump, and click once to trigger the analysis. The Memory Analyzer will create for you a report with the leak suspects. What this report contains, and how the reported leak suspects are found is described below.
Preparation
The first thing to do before starting with the analysis is to collect enough data for it. This is fairly easy - one can configure the JVM to write a heap dump whenever an OutOfMemoryError occurs. Having this setup will ensure that you get the data without having to observe the system the whole time and wait for the proper moment to trigger the dump on your own. How to configure the VM is described here (in a nutshell: add the option -XX:+HeapDumpOnOutOfMemoryError).
The second step of the preparation is to enable the memory leak to become more visible and easily detectable. To achieve this one can use the following trick: configure the maximum size of the Java heap to be much higher than the heap used when the application is running correctly (for example set it to twice the size which is usually left after a full GC). Even if you don’t know how much memory the application really needs, increasing the heap is not a bad idea (it may turn out that there is no leak but simply more heap is required). I don’t want to go into discussions if running Java applications with too big heaps is a good approach in general - simply use the tip for the time of the troubleshooting.
What do you gain by this change? On the first OutOfMemoryError the VM will write a heap dump. Most likely the size of the objects related to the leak in this heap dump will be about the half of the total heap size, i.e. it should be relatively easy to detect the leak later.
Executing the Report
Now imagine you have the heap dump which was produced by the VM as the OutOfMemoryError reoccurred. It is time to begin the leak hunting. Start the Memory Analyzer tool and load the heap dump. Already after opening the heap dump, you see an info page with a chart of the biggest objects, and in many cases you will notice a single huge object already here.
{kind=link}
But this is not the leak suspects report yet. The report, as I promised, is executed by a single click – on the “Leak Suspects” link of the overview:

Alternatively, one can execute the report using the menu from the tool bar, but it takes two clicks then ;-)
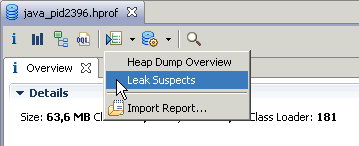
This is all you need to do. Behind the scenes we use several of the features available in the tool, and try to figure out suspiciously big objects or sets of objects. Then the findings are summarized in a comprehensive, though easy to understand HTML report. The HTML report will be displayed in the tool after it is generated. At the same time, it will be also persisted in a zip file next to the heap dump file that was provided. Thus it is very easy to ask colleagues to have a look at a specific problem, just passing them the several-kilobytes-big report, instead of transferring the whole (potentially gigabytes big) heap dump.
Content of the Report – Suspects Overview
Now let’s have a look at such a report which I have generated. As an example I have used a sample Eclipse plug-in which models a memory-leak. I called it "org.eclipse.mat.demo.leak".
This is the result I see when I do the one-click described above.

The first thing that catches my attention is a pie chart, which gives me a good visual impression about the size the suspect (the darker color). I can easily see that for my example it is about 3/4 from the whole heap.
Then follows a short description, which tells me that one instance of my LeakingQueue class, loaded by "org.eclipse.mat.demo.leak" occupies 53Mb, or 80% of the heap.
It tells me also that the memory is piled up in an instance of Object[].
So, with just two sentences the report gives me a very short and meaningful explanation where the problem is – the name of the class keeping the memory, the component to which this class belongs, how much memory is kept, and where exactly the memory is accumulated.
Note: Here the component "org.eclipse.mat.demo.leak" is actually the name of my plug-in extracted from the ClassLoader that loaded it. This is a very handy info, as even in this relatively small heap dump, there were 181 different plug-ins/classloaders. Extracting the name makes the explanation much more helpful and intuitive to understand.
Then the report offers me a set of keywords. What are they good for? One of the goals we have set for the report was to enable the discovery of already known problems. Therefore we needed to provide for each suspect a unique identifier, which people can use and search for the problem against an existing bug-tracking system. All keywords in the report (when used together) are this identifier. If the one who initially encountered the problem has provided this keywords in a bug-report, then others that encounter the same problem and use the keywords to search for a solution, should be able to find it.
Good. So far I was able with one click to see a problem suspect, and to get some info which allows me to search for a known solution. This would enable me to react on this concrete problem, even if I were not the owner of the coding, even if I didn't have any experience with troubleshooting memory-related problems.
Content of the Report – Details about the Problem
Besides an overview of the leak suspects, the report contains detailed information about each of the suspects. You can display it by following the “details” link. What details are available? Well, while looking at many different real-life problems, we found that two questions usually arise when a leak suspect is found:
Therefore, we tried to pack the answers to these two questions in the report. First, you will find in the details the shortest path from a GC root to the accumulation point:

Here you can see all the classes and fields through which the reference chain goes, and if you are familiar with the coding they should give you a good understanding how the objects are held.
Then (to answer the question why is the suspect so big) the report contains some information about the content which was accumulated:


Here, one can see which objects have been piled up - in my example these are two different types of events kept by the queue.
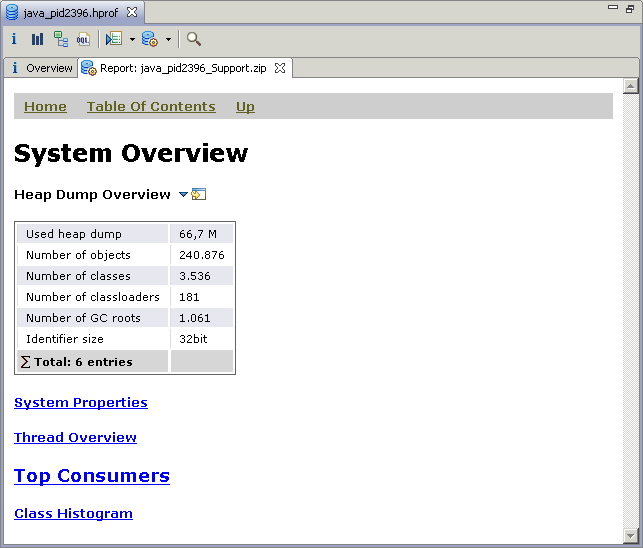
Content of the Report – System Overview
Now that we have a detailed description of the problem, let's look at one more part of the reports - the "System Overview". Once a problem is identified, questions like “In what context did this problem appear?" or "What was the environment?” may arise. To give the answer to such questions, we pack into each report a "System Overview" page. This page contains a collection of different details extracted from the heap dump, that can help you better understand the context in which the problem has appeared. These details include:
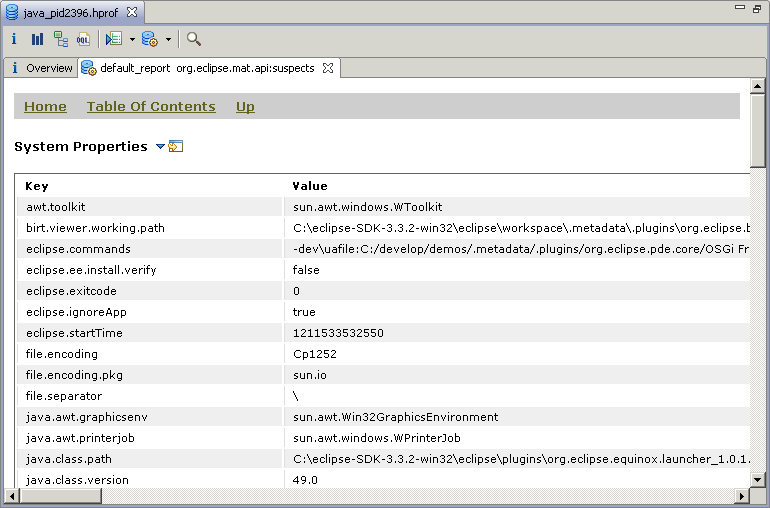
Here are two screenshots from my example - the "System Overview" start page and the "System Properties".
Behind the Scenes - Finding the Leak Suspect
Let me try now to explain how we actually find the leak suspects. When the heap dump is opened for the first time, we create several index files next to it, which enable us to access the data efficiently afterwards. During the first parsing we also build a dominator tree out of the object graph. And namely this dominator tree plays the most important role later, when we do the analysis and search for the suspects. It is difficult to explain the graph theory behind the dominator tree on a few lines only, therefore I will try to list the most important things we gain from using it:
Let me now explain how we use the dominator tree to find the leak suspects. Look at the following figure. It presents a part of the dominator tree and the size of the circles represents the retained size of the objects: the bigger the circle, the bigger the object.
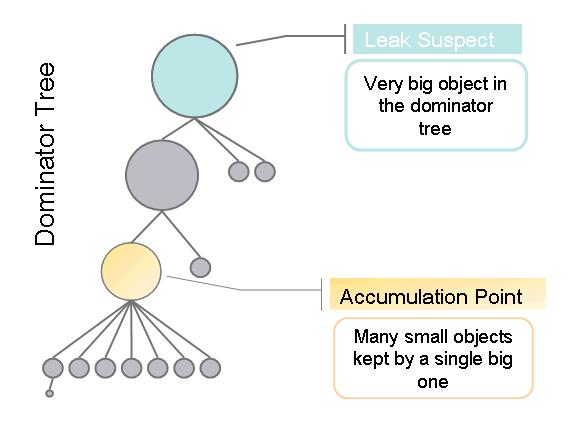
We simply treat all objects with size over a certain threshold as suspects. Then we go down the dominator tree and try to reach an object all of whose children are significantly smaller in size. This is what we call the "accumulation point". Then we just take these two objects - the suspect and the accumulation point - and use them to describe the problem.
Some more information and a description how to perform the leak hunting manually could be found in my older blog. It is based on a different version of the tool (before it became an Eclipse project) and therefore some of the buttons differ. Nevertheless, I think the explanation may help you to understand better the content of the current blog.
Conclusion
I still think that both "online" profiling and "off-line" analysis of snapshots have their strengths and limitations. I hope that I was able to demonstrate that the heap dump based memory analysis could be extremely helpful for finding memory leaks (powered by the Memory Analyzer ;-) ). Some of its advantages - no performance cost during runtime, heap dumps automatically provided by the VM on OutOfMemoryError, simplicity coming from the automated analysis - make this approach my preferred one, especially for troubleshooting productive systems.
Your feedback is highly appreciated!
Krum
Wow! This article came at a providential time. I was just struggling with a nasty memory leak yesterday, and the first thing that I read this morning was your article. Within 10 minutes of reading it, I found my memory leak! Perfect!
AntwortenLöschenThank you for the positive feedback! Now I know that I did one good deed yesterday ;-)
AntwortenLöschenJust added a blog entry to our blog, how we used the Eclipse Memory Analyzer to quickly find the memory leak in our application! Thanx for the tool, this really saved a lot of time!
AntwortenLöschenOur blog: http://blog.xebia.com/2008/09/15/beware-of-transitive-dependencies-for-they-can-be-old-and-leaky/
[...] http://dev.eclipse.org/blogs/memoryanalyzer/2008/05/27/automated-heap-dump-analysis-finding-memory-l... [...]
AntwortenLöschen[...] Automated Heap Dump Analysis: Finding Memory Leaks with One Click [...]
AntwortenLöschen[...] When analyzing generated heap dump I have found, that memory leak was caused by web application classloader, that managed thousands of CgLib dynamically generated classes. I was using Eclipse Memory Analyzer, that’s probably the best tool for memory heap dump analysis I have ever seen. It’s the third time it quickly identified the suspicious classes, by heuristic analysis called Leak suspect. [...]
AntwortenLöschen[...] Finding Memory Leaks in One Click [...]
AntwortenLöschen[...] un trabajo tremendo (Yourkit se puede integrar con Eclipse también). Pero el hecho de que Eclipse la integre de una vez es super cómodo y [...]
AntwortenLöschen[...] Automated Heap Dump Analysis: Finding Memory Leaks with One Click Posted by alextorex Filed in IT Leave a Comment » [...]
AntwortenLöschenI'm sure I'm just not seeing it somehow, but how does one open the Memory Analyzer Tool?
AntwortenLöschenIf you have installed the standalone RCP application, then there should be a MemoryAnalyzer executable in the /mat directory.
AntwortenLöschenIf you have installed just the Memory Analyzer feature to you Eclipse, then you need to open the proper perspective: Window -> Open Perspective -> Other ... -> Memory Analysis
More about installation you can find here: http://www.eclipse.org/mat/downloads.php
I hope this helps.
[...] http://dev.eclipse.org/blogs/memoryanalyzer/2008/05/27/automated-heap-dump-analysis-finding-memory-l... 32.058365 118.796468 [...]
AntwortenLöschen[...] written heap dump with MAT can be a very easy way to find the root cause of the problem (read more here). If you wan to analyze what the footprint into memory of your application is, then MAT and heap [...]
AntwortenLöschen[...] Memory Leaks Start by running the leak report to automatically check for memory leaks. This blog details How to Find a Leaking Workbench Window. [...]
AntwortenLöschenVery useful article Krum...I have a very basic (may be silly) doubt here...the heap dump obtained on outofmemory shows some significant amount of Remainder memory as well...if there is space left in heap, why is the java.lang.OutOfMemory: java heap space exception raised by JVM? Is it that the total pie not representing the heap memory alone?
AntwortenLöschenTo add to be above question...in one of our eclipse plug-in application, when we look at the dump on outofmemory (with Xmx set to 1024m), we see an object occupying 380MB, all other objects together occupying less than 100MB and reminder space around 530MB when OOM occured.
AntwortenLöschenDoes that mean now that when i try to process something on a button click (that is when OOM occured), my application is trying to create a single object which is trying to occupy more than 530MB and hence the JVM cries about memory crunch?
All the images in this article are broken links. Can they be recovered/corrected to help in following the article?
AntwortenLöschenAll the images in this article are broken links. Can they be recovered/corrected to help in following the article? +1
AntwortenLöschenI'm looking for an analysers that can use in my car, do you have idea what are analysers are? thank you.
AntwortenLöschenDieser Kommentar wurde vom Autor entfernt.
AntwortenLöschenSilk Road Research is an independent market research firm focused on providing on-the-ground business intelligence in Emerging Asia.
AntwortenLöschenDIAC Automation Gallery | DIAC Lab Photos | PLC Automation Course Images
AntwortenLöschenhttp://diac.co.in/gallery/
Our image gallery is a wonderful section. View the gallery to see lab, building, infrastructure, employee, students photos. Call for more updates 9310096831.
Here is my testimony on how I was cured of HIV by Dr Akhigbe,with his natural herbal medicine. on a regular basis in efforts to help others when I could. As you may know, each donation is tested. Well, on July 6th I had a meeting with a Red Cross representative and was told that I had HIV. “What went through your mind when you heard that "Rose" Good question reader! To be honest, I thought my life was over, that I would ever find love, get married, have children or anything normal. Lucky for me I have an amazing support system. My family supported me then I never thought that I was invincible to STD s or pregnancy or anything else parents warn their kids about. I just didn’t think about it. I was in a monogamous relationship and thought that I asked the right questions. We even talked about marriage Scary. During that time I was in college and donated blood on a re as well. who helped me in search of cure through the media.there we saw a good testimony of sister 'Kate' about the good work of Dr Akhigbe natural herbal medicine cure.then I copied his email address and contacted him. A good herbalist doctor with a good heart, he is kind, loving and caring. He replied back to my message and told me what to do. After a week the doctor sent me my herbal medicine and instructed me how to take it.Yes it worked very well, after drinking it I went to the hospital for another test and everything turned negative. What a wonderful testimony I can never forget in my life. Dr Akhigbe is a man who gave me a life to live happily forever so all I want you all to believe and know that cure of HIV is real and herbs is a powerful medicine and it works and heals. Dr Akhigbe also used his herbal medicine to cure diseases like: HERPES, DIABETES, SCABIES, HEPATITIS A/B, STROKE, CANCER, ALS, TUBERCULOSIS, ASTHMA, PENIS ENLARGEMENT, MALARIA, LUPUS, LIVER CIRRHOSIS, DEPRESSION, HIV/AIDS, EPILEPSY, BACTERIAL, DIARRHEA, HEART DISEASES, HIGH BLOOD PRESSURE, PARKINSON'S, ALZHEIMER, COLD URTICARIA, HUMAN PAPILLOMAVIRUS,INSOMNIA, BACTERIAL VAGINOSIS, SCHIZOPHRENIA, JOINT PAIN, STOMACH PAIN, CHROME DISEASES, CHLAMYDIA, INSOMNIA HEARTBURN, , THYROID, MAR BURG DISEASES, MENINGITIS, ARTHRITIS, BODY WEAK, SMALLPOX, DENGUE, FEVER, CURBS, CHANCRE, AND OTHERS VARIOUS DISEASES/ VIRUS. You are there and you find yourself in any of these situations, kindly contact Dr Akhigbe now to help you get rid of it. Here is his email address:
AntwortenLöschendrrealakhigbe@gmail.com or you can write to him on whats app with his phone number: +2349010754824.
My appreciation is to share his testimony for the world to know the good work Dr Akhigbe has done for me and he will do the same for you.
https://www.sdn.sap.com/irj/sdn/weblogs?blog=/pub/wlg/6856 Your older blog can't acess, where can I find it.
AntwortenLöschenInteresting, I saw your article on google, very interesting to read. I have seen this blog, it is very nice to read and has more informative information. Feel free to visit my website; 바카라사이트
AntwortenLöschenThis post is good enough to make somebody understand this amazing thing, and I’m sure everyone will appreciate this interesting things. Visit our website too. Feel free to visit my website; 바카라
AntwortenLöschenhttps://jasapengirimankontainer.com/2023/04/18/jasa-ekspedisi-kontainer-kalimatan-timurtermurah/
AntwortenLöschenhttps://jasapengirimankontainer.com/2023/04/08/jasa-ekspedisi-kontainer-surabaya-ke-kalimatan-tengah/
https://www.auraabadilogistik.com/ekspedisi-motor-surabaya-batu-kajang/
https://www.auraabadilogistik.com/jasa-kirim-motor-surabaya-bengkayang/
https://pengirimanantarpulau.com/ekspedisi-surabaya-ke-borang-kab-manggarai-timur-aman-dan-terpercaya/
https://pengirimanantarpulau.com/ekspedisi-surabaya-ke-larantuka-kab-flores-timur-tarif-murah/
Choosing the right ph orp analyzer online can improve efficiency, reduce downtime, and provide real-time data for better process control.
AntwortenLöschen